Upgrade to 3.5 and 7.5
1. Upgrade to 3.5 and 7.5
RDAF Infra Upgrade: 1.0.3.2 (haproxy)
RDAF Platform: From 3.4.2.x to 3.5
AIOps (OIA) Application: From 7.4.2.x to 7.5
RDAF Deployment rdafk8s CLI: From 1.2.2 to 1.3.0
RDAF Client rdac CLI: From 3.4.2.x to 3.5
RDAF Infra Upgrade: 1.0.3.2 (haproxy)
RDAF Platform: From 3.4.2.x to 3.5
OIA (AIOps) Application: From 7.4.2.x to 7.5
RDAF Deployment rdaf CLI: From 1.2.2 to 1.3.0
RDAF Client rdac CLI: From 3.4.2.x to 3.5
1.1. Prerequisites
Before proceeding with this upgrade, please make sure and verify the below prerequisites are met.
Currently deployed CLI and RDAF services are running the below versions.
-
RDAF Deployment CLI version: 1.2.2
-
Infra Services tag: 1.0.3 / 1.0.3.2 (haproxy)
-
Platform Services and RDA Worker tag: 3.4.2 / 3.4.2.1 (rda-scheduler, rda-api-server), 3.4.2.2 (rda-resource-manager, rda-portal)
-
OIA Application Services tag: 7.4.2 / 7.4.2.1 (rda-webhook-server, rda-alert-processor, rda-event-consumer, rda-smtp-server)
-
CloudFabrix recommends taking VMware VM snapshots where RDA Fabric infra/platform/applications are deployed
Note
- Check the Disk space of all the Platform and Service Vm's using the below mentioned command, the highlighted disk size should be less than 80%
rdauser@oia-125-216:~/collab-3.5-upgrade$ df -kh
Filesystem Size Used Avail Use% Mounted on
udev 32G 0 32G 0% /dev
tmpfs 6.3G 357M 6.0G 6% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 48G 12G 34G 26% /
tmpfs 32G 0 32G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/loop0 64M 64M 0 100% /snap/core20/2318
/dev/loop2 92M 92M 0 100% /snap/lxd/24061
/dev/sda2 1.5G 309M 1.1G 23% /boot
/dev/sdf 50G 3.8G 47G 8% /var/mysql
/dev/loop3 39M 39M 0 100% /snap/snapd/21759
/dev/sdg 50G 541M 50G 2% /minio-data
/dev/loop4 92M 92M 0 100% /snap/lxd/29619
/dev/loop5 39M 39M 0 100% /snap/snapd/21465
/dev/sde 15G 140M 15G 1% /zookeeper
/dev/sdd 30G 884M 30G 3% /kafka-logs
/dev/sdc 50G 3.3G 47G 7% /opt
/dev/sdb 50G 29G 22G 57% /var/lib/docker
/dev/sdi 25G 294M 25G 2% /graphdb
/dev/sdh 50G 34G 17G 68% /opensearch
/dev/loop6 64M 64M 0 100% /snap/core20/2379
- Check all MariaDB nodes are sync on HA setup using below commands before start upgrade
Tip
Please run the below commands on the VM host where RDAF deployment CLI was installed and rdafk8s setup command was run. The mariadb configuration is read from /opt/rdaf/rdaf.cfg file.
MARIADB_HOST=`cat /opt/rdaf/rdaf.cfg | grep -A3 mariadb | grep datadir | awk '{print $3}' | cut -f1 -d'/'`
MARIADB_USER=`cat /opt/rdaf/rdaf.cfg | grep -A3 mariadb | grep user | awk '{print $3}' | base64 -d`
MARIADB_PASSWORD=`cat /opt/rdaf/rdaf.cfg | grep -A3 mariadb | grep password | awk '{print $3}' | base64 -d`
mysql -u$MARIADB_USER -p$MARIADB_PASSWORD -h $MARIADB_HOST -P3307 -e "show status like 'wsrep_local_state_comment';"
Please verify that the mariadb cluster state is in Synced state.
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| wsrep_local_state_comment | Synced |
+---------------------------+--------+
Please run the below command and verify that the mariadb cluster size is 3.
mysql -u$MARIADB_USER -p$MARIADB_PASSWORD -h $MARIADB_HOST -P3307 -e "SHOW GLOBAL STATUS LIKE 'wsrep_cluster_size'";
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
Warning
Make sure all of the above pre-requisites are met before proceeding with the upgrade process.
Warning
Kubernetes: Though Kubernetes based RDA Fabric deployment supports zero downtime upgrade, it is recommended to schedule a maintenance window for upgrading RDAF Platform and AIOps services to newer version.
Important
Please make sure full backup of the RDAF platform system is completed before performing the upgrade.
Kubernetes: Please run the below backup command to take the backup of application data.
Run the below command on RDAF Management system and make sure the Kubernetes PODs are NOT in restarting mode (it is applicable to only Kubernetes environment)
- Verify that RDAF deployment
rdafcli version is 1.2.2 on the VM where CLI was installed for docker on-prem registry managing Kubernetes or Non-kubernetes deployments.
- On-premise docker registry service version is 1.0.3
ff6b1de8515f cfxregistry.CloudFabrix.io:443/docker-registry:1.0.3 "/entrypoint.sh /bin…" 7 days ago Up 7 days deployment-scripts-docker-registry-1
-
RDAF Infrastructure services version is 1.0.3 except for below services.
-
rda-minio: version is
RELEASE.2023-09-30T07-02-29Z -
haproxy: version is 1.0.3.2
Run the below command to get rdafk8s Infra service details
- RDAF Platform services version is 3.4.2.x
Run the below command to get RDAF Platform services details
- RDAF OIA Application services version is 7.4.2.x
Run the below command to get RDAF App services details
-
RDAF Deployment CLI version: 1.2.2
-
Infra Services tag: 1.0.3 / 1.0.3.2 (haproxy)
-
Platform Services and RDA Worker tag: 3.4.2 / 3.4.2.1 (rda_scheduler, rda_api_server), 3.4.2.2(cfx-rda-resource-manager, portal-backend, portal-frontend)
-
OIA Application Services tag: 7.4.2 / 7.4.2.1(cfx-rda-webhook-server,cfx-rda-alert-processor,cfx-rda-event-consumer,cfx-rda-smtp-server)
-
CloudFabrix recommends taking VMware VM snapshots where RDA Fabric infra/platform/applications are deployed
Note
- Check the Disk space of all the Platform and Service Vm's using the below mentioned command, the highlighted disk size should be less than 80%
rdauser@oia-125-216:~/collab-3.5-upgrade$ df -kh
Filesystem Size Used Avail Use% Mounted on
udev 32G 0 32G 0% /dev
tmpfs 6.3G 357M 6.0G 6% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 48G 12G 34G 26% /
tmpfs 32G 0 32G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/loop0 64M 64M 0 100% /snap/core20/2318
/dev/loop2 92M 92M 0 100% /snap/lxd/24061
/dev/sda2 1.5G 309M 1.1G 23% /boot
/dev/sdf 50G 3.8G 47G 8% /var/mysql
/dev/loop3 39M 39M 0 100% /snap/snapd/21759
/dev/sdg 50G 541M 50G 2% /minio-data
/dev/loop4 92M 92M 0 100% /snap/lxd/29619
/dev/loop5 39M 39M 0 100% /snap/snapd/21465
/dev/sde 15G 140M 15G 1% /zookeeper
/dev/sdd 30G 884M 30G 3% /kafka-logs
/dev/sdc 50G 3.3G 47G 7% /opt
/dev/sdb 50G 29G 22G 57% /var/lib/docker
/dev/sdi 25G 294M 25G 2% /graphdb
/dev/sdh 50G 34G 17G 68% /opensearch
/dev/loop6 64M 64M 0 100% /snap/core20/2379
Warning
Make sure all of the above pre-requisites are met before proceeding with the upgrade process.
Warning
Non-Kubernetes: Upgrading RDAF Platform and AIOps application services is a disruptive operation. Schedule a maintenance window before upgrading RDAF Platform and AIOps services to newer version.
Important
Please make sure full backup of the RDAF platform system is completed before performing the upgrade.
Non-Kubernetes: Please run the below backup command to take the backup of application data.
Note: Please make sure this backup-dir is mounted across all infra,cli vms.- Verify that RDAF deployment
rdafcli version is 1.2.2 on the VM where CLI was installed for docker on-prem registry managing Kubernetes or Non-kubernetes deployments.
- On-premise docker registry service version is 1.0.3
ff6b1de8515f cfxregistry.CloudFabrix.io:443/docker-registry:1.0.3 "/entrypoint.sh /bin…" 7 days ago Up 7 days deployment-scripts-docker-registry-1
-
RDAF Infrastructure services version is 1.0.3 except for below services.
-
rda-minio: version is
RELEASE.2023-09-30T07-02-29Z -
haproxy: version is
1.0.3.2
Run the below command to get RDAF Infra service details
- RDAF Platform services version is 3.4.2 or 3.4.2.x
Run the below command to get RDAF Platform services details
- RDAF OIA Application services version is 7.4.2 or 7.4.2.x
Run the below command to get RDAF App services details
1.1.1 Update Pstream Settings
Warning
Before starting the upgrade of the RDAF platform's version to 3.5/7.5 release, please complete the below 2 steps which are mandatory.
-
Update the below mentioned pstream settings, before starting the upgrade of RDAF CLI from version 1.2.2 to 1.3.0. These steps are mandatory and only applicable if the CFX RDAF AIOps (OIA) application services are installed. Otherwise, please ignore them.
-
Migrate the Collaboration application service's data from the Database to Pstreams
- Navigate to Main Menu --> Configuration --> RDA Administration --> Persistent Streams --> Persistent Streams. Edit and update the pstream settings as highlighted below.
a) oia-source-events-stream: Update the pstream settings by adding the field mappings (data type) for the below mentioned field names. These are newly introduced in this release upgrade. Additionally, add the filter retention_purge_extra_filter setting which is applied while purging the data.
- se_createdat
- se_sourcereceivedat
- se_updatedat
{
"unique_keys": [
"se_id"
],
"computed_columns": {
"customer_id": {
"expr": "se_customerid"
},
"project_id": {
"expr": "se_projectid"
}
},
"_mappings": {
"properties": {
"se_createdat": {
"type": "date"
},
"se_sourcereceivedat": {
"type": "date"
},
"se_updatedat": {
"type": "date"
}
}
},
"default_values": {
"se_sourcesystemname": "Not Available",
"se_status": "Not Available"
},
"retention_days": 3,
"retention_purge_extra_filter": "se_status != 'Failed' or timestamp is before -30 days",
"case_insensitive": true
}
b) oia-events-stream: Update the pstream settings by adding the field mappings (data type) for the below mentioned field names. These are newly introduced in this release upgrade. Additionally, add the filter retention_purge_extra_filter setting which is applied while purging the data.
- e_createdat
- e_sourcereceivedat
- e_updatedat
{
"unique_keys": [
"e_id"
],
"computed_columns": {
"customer_id": {
"expr": "e_customerid"
},
"project_id": {
"expr": "e_projectid"
}
},
"_mappings": {
"properties": {
"e_createdat": {
"type": "date"
},
"e_sourcereceivedat": {
"type": "date"
},
"e_updatedat": {
"type": "date"
}
}
},
"default_values": {
"e_sourcesystemname": "Not Available",
"e_eventstate": "Not Available",
"e_status": "Not Available"
},
"retention_days": 3,
"retention_purge_extra_filter": "e_status != 'Failed' or timestamp is before -30 days",
"case_insensitive": true
}
c) oia-event-trail-stream: Update the pstream settings by adding the unique_keys as highlighted and the field mappings (data type) for the below mentioned field names. These are newly introduced in this release upgrade. Additionally, add the filter retention_purge_extra_filter setting which is applied while purging the data.
- et_createdat
{
"unique_keys": [
"et_id"
],
"computed_columns": {
"customer_id": {
"expr": "et_customerid"
},
"project_id": {
"expr": "et_projectid"
}
},
"_mappings": {
"properties": {
"et_createdat": {
"type": "date"
}
}
},
"retention_days": 3,
"retention_purge_extra_filter": "et_status != 'Failed'or timestamp is before -30 days",
"case_insensitive": true
}
1.1.2 Download the new Docker Images
Download the new docker image tags for RDAF Platform and OIA (AIOps) Application services and wait until all of the images are downloaded.
To fetch registry please use the below command
Note
If the Download of the images fail, Please re-execute the above command
Run the below command to verify above mentioned tags are downloaded for all of the RDAF Platform and OIA (AIOps) Application services.
Please make sure 3.5 image tag is downloaded for the below RDAF Platform services.
- rda-client-api-server
- rda-registry
- rda-rda-scheduler
- rda-collector
- rda-identity
- rda-fsm
- rda-asm
- rda-stack-mgr
- rda-access-manager
- rda-resource-manager
- rda-user-preferences
- onprem-portal
- onprem-portal-nginx
- rda-worker-all
- onprem-portal-dbinit
- cfxdx-nb-nginx-all
- rda-event-gateway
- rda-chat-helper
- rdac
- rdac-full
- cfxcollector
- rda-rda-scheduler
- rda-client-api-server
- rda-worker-all
- cfxdx-nb-nginx-all
- rdac
- rdac-full
- bulk_stats
Please make sure 7.5 image tag is downloaded for the below RDAF OIA (AIOps) Application services.
- rda-app-controller
- rda-alert-processor
- rda-file-browser
- rda-smtp-server
- rda-ingestion-tracker
- rda-reports-registry
- rda-ml-config
- rda-event-consumer
- rda-webhook-server
- rda-irm-service
- rda-alert-ingester
- rda-collaboration
- rda-notification-service
- rda-configuration-service
- rda-irm-service
- rda-alert-processor-companion
- rda-event-consumer
- rda-webhook-server
- rda-alert-processor
- rda-smtp-server
Downloaded Docker images are stored under the below path.
/opt/rdaf-registry/data/docker/registry/v2/ or /opt/rdaf/data/docker/registry/v2/
Run the below command to check the filesystem's disk usage on offline registry VM where docker images are pulled.
If necessary, older image tags that are no longer in use can be deleted to free up disk space using the command below.
Note
Run the command below if /opt occupies more than 80% of the disk space or if the free capacity of /opt is less than 25GB.
1.1.3 Migrate Collaboration Service Data
Collaboration service's data migration from Database to Pstreams:
Please refer Collaboration service's data migration from Database to Pstream
Warning
Please proceed to the next step only after the Collaboration Service's data migration has completed successfully.
RDAF Deployment CLI Upgrade:
Please follow the below given steps.
Note
Upgrade RDAF Deployment CLI on both on-premise docker registry VM and RDAF Platform's management VM if provisioned separately.
Login into the VM where rdaf deployment CLI was installed for docker on-premise registry and managing Kubernetes or Non-kubernetes deployment.
- Download the RDAF Deployment CLI's newer version 1.3.0 bundle.
- Upgrade the
rdafk8sCLI to version 1.3.0
- Verify the installed
rdafk8sCLI version is upgraded to 1.3.0
- Download the RDAF Deployment CLI's newer version 1.3.0 bundle and copy it to RDAF CLI management VM on which
rdafdeployment CLI was installed.
- Extract the
rdafCLI software bundle contents
- Change the directory to the extracted directory
- Upgrade the
rdafCLI to version 1.3.0
- Verify the installed
rdafCLI version
- Extract the
rdafCLI software bundle contents
- Change the directory to the extracted directory
- Upgrade the
rdafCLI to version 1.3.0
- Verify the installed
rdafCLI version
- Download the RDAF Deployment CLI's newer version 1.3.0 bundle
- Upgrade the
rdafCLI to version 1.3.0
- Verify the installed
rdafCLI version is upgraded to 1.3.0
- Download the RDAF Deployment CLI's newer version 1.3.0 bundle and copy it to RDAF management VM on which
rdaf & rdafk8sdeployment CLI was installed.
- Extract the
rdafCLI software bundle contents
- Change the directory to the extracted directory
- Upgrade the
rdafCLI to version 1.3.0
- Verify the installed
rdafCLI version
- Extract the
rdafCLI software bundle contents
- Change the directory to the extracted directory
- Upgrade the
rdafCLI to version 1.3.0
- Verify the installed
rdafCLI version
1.3. Upgrade Steps
1.3.1 Upgrade RDAF Infra Services
Please download the below python script (rdaf_upgrade_122_to_130.py)
The below step will generate values.yaml.latest files for all RDAF Infrastructure, Platform and Application services in the /opt/rdaf/deployment-scripts directory.
Note
On the CLI VM please make sure policy.json file exists in this path /opt/rdaf/config/network_config, If the policy.json file does not exist please copy it from the platform VM. Do SSH to Platform VM and execute the below command
scp -r /opt/rdaf/config/network_config/policy.json rdauser@<clivm IP>:/opt/rdaf/config/network_config
The upgrade script makes the below changes.
-
In this upgrade, the Redis configuration would get cleared in
values.yaml -
Copy the
/opt/rdaf/rdaf.cfgfile to all RDAF platform's infra, platform, application and worker service hosts, maintaining the same directory path. -
Copy the
/opt/rdaf/config/network_config/policy.jsonfile to both the platform and service hosts, maintaining the same directory path. -
The RDAF platform 3.5 release added support for
bulkstatsas part of it's performance management solution. Configuration related to the Bulkstats service has been added to the/opt/rdaf/deployment-scripts/values.yamlfile. -
In
haproxy.cfgfile backend mariadb section should look same as shown below, path of the file (on HAProxy VM:/opt/rdaf/config/haproxy/haproxy.cfg)
backend mariadb
mode tcp
balance roundrobin
option tcpka
timeout server 28800s
default-server inter 10s downinter 5s
option external-check
external-check command /maria_cluster_check
server mariadb-192.168.133.97 192.168.133.97:3306 check backup
server mariadb-192.168.133.98 192.168.133.98:3306 check
server mariadb-192.168.133.99 192.168.133.99:3306 check backup
Note
The above config change is applicable only for HA Environments
Please follow the below steps to upgrade the configuration for below platform and OIA (AIOps) application services by updating the /opt/rdaf/deployment-scripts/values.yaml
- rda-portal-backend
- rda-fsm
- rda-alert-processor
- rda-collector
rda-portal-backend: Add the new environment variable CFX_URL_PREFIX to the portal_backend service. If the CFX_URL_PREFIX environment variable is already configured for the portal_frontend service (e.g., aiops), please ensure that the same value is applied to the portal_backend service as well. If no value is configured for CFX_URL_PREFIX, leave it empty.
| values.yaml.backup (existing config) | values.yaml (updated config) |
|---|---|
|
|
rda-fsm: Add the new environment variables KAFKA_CONSUMER_BATCH_MAX_SIZE and KAFKA_CONSUMER_BATCH_MAX_TIME_SECONDS to the rda_fsm service as highlighted below.
alert_processor: Add the new environment variables RDA_DB_CONNECTION_MAX_OVERFLOW and RDA_DB_CONNECTION_INITIAL_POOL_SIZE to the alert_processor service as highlighted below.
rda_collector: Set the privileged value to true and include the cap_add parameter in the new configuration. This adjustment ensures that the rda_collector service has the necessary permissions to collect the traces for debugging and troubleshooting purposes.
Note
The following settings apply to all RDAF platform and application services (excluding Infra services). Updating these settings is optional for this upgrade, but if possible, please make the updates.
| values.yaml.backup (existing config) | values.yaml (updated config) |
|---|---|
|
|
- Upgrade haproxy service using below command. Although the tag provided is the same as the existing one, the command below applies a log rotation fix for the haproxy service.
- Please use the below mentioned command to see haproxy is up and in Running state.
+--------------------------+----------------+-----------------+--------------+------------------------------+
| Name | Host | Status | Container Id | Tag |
+--------------------------+----------------+-----------------+--------------+------------------------------+
| haproxy | 192.168.108.13 | Up 7 hours | acb0535d47f6 | 1.0.3.2 |
| haproxy | 192.168.108.14 | Up 7 hours | 292fa79d6066 | 1.0.3.2 |
| keepalived | 192.168.108.13 | active | N/A | N/A |
| keepalived | 192.168.108.14 | active | N/A | N/A |
| rda-nats | 192.168.108.13 | Up 8 Hours ago | e31ffb44d023 | 1.0.3 |
| rda-nats | 192.168.108.14 | Up 8 Hours ago | bd39199e9dff | 1.0.3 |
| rda-minio | 192.168.108.13 | Up 8 Hours ago | fcdd4fc0f339 | RELEASE.2023-09-30T07-02-29Z |
| rda-minio | 192.168.108.14 | Up 8 Hours ago | def48fd1761c | RELEASE.2023-09-30T07-02-29Z |
| rda-minio | 192.168.108.16 | Up 8 Hours ago | e51f463de10e | RELEASE.2023-09-30T07-02-29Z |
| rda-minio | 192.168.108.17 | Up 8 Hours ago | 5d34e867a079 | RELEASE.2023-09-30T07-02-29Z |
| -mariadb | 192.168.108.13 | Up 2 Hours ago | dda4b0dc1fad | 1.0.3 |
| rda-mariadb | 192.168.108.14 | Up 2 Hours ago | d80d5d844ec4 | 1.0.3 |
+--------------------------+----------------+-----------------+--------------+------------------------------+
Please download the below python script (rdaf_upgrade_122_to_130.py)
The below step will generate values.yaml.latest files for all RDAF Infrastructure, Platform and Application services in the /opt/rdaf/deployment-scripts directory.
Note
On the CLI VM please make sure policy.json file exists in this path /opt/rdaf/config/network_config, If the policy.json file does not exist please copy it from the platform VM. Do SSH to Platform VM and execute the below command
scp -r /opt/rdaf/config/network_config/policy.json rdauser@<clivm IP>:/opt/rdaf/config/network_config
The upgrade script makes the below changes.
-
In this upgrade, as the Redis infrastructure service is deprecated and no longer needed, the Redis service related PODs, configuration will be cleared.
-
Copy the
/opt/rdaf/rdaf.cfgfile to all RDAF platform's infra, platform, application and worker service hosts, maintaining the same directory path. -
Copy the
/opt/rdaf/config/network_config/policy.jsonfile to both the platform and service hosts, maintaining the same directory path. -
The RDAF platform 3.5 release added support for
bulkstatsas part of it's performance management solution. Configuration related to the Bulkstats service has been added to the/opt/rdaf/deployment-scripts/values.yamlfile. -
In
haproxy.cfgfile backend mariadb section should look same as shown below, path of the file (on HAProxy VM:/opt/rdaf/config/haproxy/haproxy.cfg)
backend mariadb
mode tcp
balance roundrobin
option tcpka
timeout server 28800s
default-server inter 10s downinter 5s
option external-check
external-check command /maria_cluster_check
server mariadb-192.168.133.97 192.168.133.97:3306 check backup
server mariadb-192.168.133.98 192.168.133.98:3306 check
server mariadb-192.168.133.99 192.168.133.99:3306 check backup
Note
The above config change is applicable only for HA Environments
Please follow the below steps to upgrade the configuration for below platform and OIA (AIOps) application services by updating the /opt/rdaf/deployment-scripts/values.yaml
- portal-backend
- rda_fsm
- cfx-rda-alert-processor
- rda_collector
portal-backend: Add the new environment variable CFX_URL_PREFIX to the portal-backend service. If the CFX_URL_PREFIX environment variable is already configured for the portal-frontend service (e.g., aiops), please ensure that the same value is applied to the portal-backend service as well. If no value is configured for CFX_URL_PREFIX, leave it empty.
| values.yaml.backup (existing config) | values.yaml (updated config) |
|---|---|
|
|
rda_fsm: Add the new environment variables KAFKA_CONSUMER_BATCH_MAX_SIZE and KAFKA_CONSUMER_BATCH_MAX_TIME_SECONDS to the rda_fsm service as highlighted below.
alert_processor: Add the new environment variables RDA_DB_CONNECTION_MAX_OVERFLOW and RDA_DB_CONNECTION_INITIAL_POOL_SIZE to the alert_processor service as highlighted below.
rda_collector: Set the privileged value to true and include the cap_add parameter in the new configuration. This adjustment ensures that the rda_collector service has the necessary permissions to collect the traces for debugging and troubleshooting purposes.
Note
The following settings apply to all RDAF platform and application services (excluding Infra services). Updating these settings is optional for this upgrade, but if possible, please make the updates.
| values.yaml.backup (existing config) | values.yaml (updated config) |
|---|---|
|
|
- Upgrade haproxy service using below command. Although the tag provided is the same as the existing one, the command below applies a log rotation fix for the haproxy service.
- Please use the below mentioned command to see haproxy is up and in Running state
+----------------------+----------------+-----------------+--------------+------------------------------+
| Name | Host | Status | Container Id | Tag |
+----------------------+----------------+-----------------+--------------+------------------------------+
| haproxy | 192.168.133.97 | Up 22 hours | 5016d26a4c88 | 1.0.3.2 |
| haproxy | 192.168.133.98 | Up 22 hours | 73b4f0a8235f | 1.0.3.2 |
| keepalived | 192.168.133.97 | active | N/A | N/A |
| keepalived | 192.168.133.98 | active | N/A | N/A |
| nats | 192.168.133.97 | Up 43 hours | 2342eb72fbd6 | 1.0.3 |
| nats | 192.168.133.98 | Up 43 hours | 745cedb9ade6 | 1.0.3 |
| minio | 192.168.133.93 | Up 43 hours | 67f4017a19bf | RELEASE.2023-09-30T07-02-29Z |
| minio | 192.168.133.97 | Up 43 hours | 7519e544135c | RELEASE.2023-09-30T07-02-29Z |
| minio | 192.168.133.98 | Up 43 hours | 655ba3058fb0 | RELEASE.2023-09-30T07-02-29Z |
| minio | 192.168.133.99 | Up 43 hours | 44d987601c56 | RELEASE.2023-09-30T07-02-29Z |
| mariadb | 192.168.133.97 | Up 43 hours | 24bded0556bb | 1.0.3 |
| mariadb | 192.168.133.98 | Up 43 hours | 59ac3e182890 | 1.0.3 |
+----------------------+----------------+-----------------+--------------+------------------------------+
Run the below RDAF command to check infra healthcheck status
+----------------+-----------------+--------+------------------------------+----------------+--------------+
| Name | Check | Status | Reason | Host | Container Id |
+----------------+-----------------+--------+------------------------------+----------------+--------------+
| haproxy | Port Connection | OK | N/A | 192.168.133.97 | 5016d26a4c88 |
| haproxy | Service Status | OK | N/A | 192.168.133.97 | 5016d26a4c88 |
| haproxy | Firewall Port | OK | N/A | 192.168.133.97 | 5016d26a4c88 |
| haproxy | Port Connection | OK | N/A | 192.168.133.98 | 73b4f0a8235f |
| haproxy | Service Status | OK | N/A | 192.168.133.98 | 73b4f0a8235f |
| haproxy | Firewall Port | OK | N/A | 192.168.133.98 | 73b4f0a8235f |
| keepalived | Service Status | OK | N/A | 192.168.133.97 | N/A |
| keepalived | Service Status | OK | N/A | 192.168.133.98 | N/A |
| nats | Port Connection | OK | N/A | 192.168.133.97 | 2342eb72fbd6 |
| nats | Service Status | OK | N/A | 192.168.133.97 | 2342eb72fbd6 |
| nats | Firewall Port | OK | N/A | 192.168.133.97 | 2342eb72fbd6 |
| nats | Port Connection | OK | N/A | 192.168.133.98 | 745cedb9ade6 |
| nats | Service Status | OK | N/A | 192.168.133.98 | 745cedb9ade6 |
| nats | Firewall Port | OK | N/A | 192.168.133.98 | 745cedb9ade6 |
| minio | Port Connection | OK | N/A | 192.168.133.93 | 67f4017a19bf |
| minio | Service Status | OK | N/A | 192.168.133.93 | 67f4017a19bf |
| minio | Firewall Port | OK | N/A | 192.168.133.93 | 67f4017a19bf |
| minio | Port Connection | OK | N/A | 192.168.133.97 | 7519e544135c |
+----------------+-----------------+--------+------------------------------+----------------+--------------+
1.3.2 Upgrade RDAF Platform Services
Step-1: Run the below command to initiate upgrading RDAF Platform services.
As the upgrade procedure is a non-disruptive upgrade, it puts the currently running PODs into Terminating state and newer version PODs into Pending state.
Step-2: Run the below command to check the status of the existing and newer PODs and make sure atleast one instance of each Platform service is in Terminating state.
Step-3: Run the below command to put all Terminating RDAF platform service PODs into maintenance mode. It will list all of the POD Ids of platform services along with rdac maintenance command that required to be put in maintenance mode.
Note
If maint_command.py script doesn't exist on RDAF deployment CLI VM, it can be downloaded using the below command.
Step-4: Copy & Paste the rdac maintenance command as below.
Step-5: Run the below command to verify the maintenance mode status of the RDAF platform services.
Step-6: Run the below command to delete the Terminating RDAF platform service PODs
for i in `kubectl get pods -n rda-fabric -l app_category=rdaf-platform | grep 'Terminating' | awk '{print $1}'`; do kubectl delete pod $i -n rda-fabric --force; done
Note
Wait for 120 seconds and Repeat above steps from Step-2 to Step-6 for rest of the RDAF Platform service PODs.
Please wait till all of the new platform service PODs are in Running state and run the below command to verify their status and make sure all of them are running with 3.5 version.
+----------------------+----------------+-----------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+----------------------+----------------+-----------------+--------------+-------+
| rda-api-server | 192.168.108.18 | Up 20 Hours ago | 2a82e1c61a68 | 3.5 |
| rda-api-server | 192.168.108.19 | Up 20 Hours ago | df62a70a6c1a | 3.5 |
| rda-registry | 192.168.108.17 | Up 20 Hours ago | 13c315828636 | 3.5 |
| rda-registry | 192.168.108.20 | Up 20 Hours ago | 20b6face1f0f | 3.5 |
| rda-identity | 192.168.108.20 | Up 20 Hours ago | 2bad61339cde | 3.5 |
| rda-identity | 192.168.108.17 | Up 20 Hours ago | d9ae0addbec0 | 3.5 |
| rda-fsm | 192.168.108.20 | Up 20 Hours ago | 737017f12ce0 | 3.5 |
| rda-fsm | 192.168.108.17 | Up 20 Hours ago | be6fed12f025 | 3.5 |
| rda-asm | 192.168.108.20 | Up 20 Hours ago | b02017f13c74 | 3.5 |
| rda-asm | 192.168.108.17 | Up 20 Hours ago | 105f923b7094 | 3.5 |
| rda-chat-helper | 192.168.108.17 | Up 20 Hours ago | 877a555c57d1 | 3.5 |
| rda-chat-helper | 192.168.108.20 | Up 20 Hours ago | 8993a2ca5ec7 | 3.5 |
| rda-access-manager | 192.168.108.17 | Up 20 Hours ago | 437f72d1cd29 | 3.5 |
| rda-access-manager | 192.168.108.20 | Up 20 Hours ago | 74082772a617 | 3.5 |
+----------------------+----------------+-----------------+--------------+-------+
Run the below command to check the rda-scheduler service is elected as a leader under Site column.
+-------+----------------------------------------+-------------+--------------+----------+-------------+-----------------+--------+--------------+---------------+--------------+
| Cat | Pod-Type | Pod-Ready | Host | ID | Site | Age | CPUs | Memory(GB) | Active Jobs | Total Jobs |
|-------+----------------------------------------+-------------+--------------+----------+-------------+-----------------+--------+--------------+---------------+--------------|
| Infra | api-server | True | rda-api-server | 9c0484af | | 11:41:50 | 8 | 31.33 | | |
| Infra | api-server | True | rda-api-server | 196558ed | | 11:40:23 | 8 | 31.33 | | |
| Infra | asm | True | rda-asm-5b8fb9 | bcbdaae5 | | 11:42:26 | 8 | 31.33 | | |
| Infra | asm | True | rda-asm-5b8fb9 | 232a58af | | 11:42:40 | 8 | 31.33 | | |
| Infra | collector | True | rda-collector- | d06fb56c | | 11:42:03 | 8 | 31.33 | | |
| Infra | collector | True | rda-collector- | a4c79e4c | | 11:41:59 | 8 | 31.33 | | |
| Infra | registry | True | rda-registry-6 | 2fd69950 | | 11:42:03 | 8 | 31.33 | | |
| Infra | registry | True | rda-registry-6 | fac544d6 | | 11:41:59 | 8 | 31.33 | | |
| Infra | scheduler | True | rda-scheduler- | b98afe88 | *leader* | 11:42:01 | 8 | 31.33 | | |
| Infra | scheduler | True | rda-scheduler- | e25a0841 | | 11:41:56 | 8 | 31.33 | | |
| Infra | worker | True | rda-worker-5b5 | 99bd054e | rda-site-01 | 11:33:40 | 8 | 31.33 | 0 | 0 |
| Infra | worker | True | rda-worker-5b5 | 0bfdcd98 | rda-site-01 | 11:33:34 | 8 | 31.33 | 0 | 0 |
+-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------+
Run the below command to check if all services has ok status and does not throw any failure messages.
Redis service cleanup:
Run the Python script mentioned below to clean up the redis infrastructure service. This script will:
- Shut down the redis service.
- Clear configuration data in
/opt/rdaf/rdaf.cfg,/opt/rdaf/deployment-scripts/redis-values.yaml, andhelm/redis - Uninstall the service using Helm.
- Remove Persistent Volume Claims (PVCs) and Persistent Volumes (PVs).
- Infrastructure service is deprecated and no longer needed, the Redis service related PODs gets deleted
- Run the below mentioned command to check if redis service PODs are decommissioned.
Warning
For Non-Kubernetes deployment, upgrading RDAF Platform and AIOps application services is a disruptive operation when rolling-upgrade option is not used. Please schedule a maintenance window before upgrading RDAF Platform and AIOps services to newer version.
Run the below command to initiate upgrading RDAF Platform services with zero downtime
Note
timeout <10> mentioned in the above command represents as Seconds
Note
The rolling-upgrade option upgrades the Platform services running in high-availability mode on one VM at a time in sequence. It completes the upgrade of Platform services running on VM-1 before upgrading them on VM-2, followed by VM-3, and so on.
During this upgrade sequence, RDAF platform continues to function without any impact to the application traffic.
After completing the Platform services upgrade on all VMs, it will ask for user confirmation to delete the older version Platform service PODs. The user has to provide YES to delete the old pods
192.168.133.95:5000/onprem-portal-nginx:3.5
2024-08-12 02:21:58,875 [rdaf.component.platform] INFO - Gathering platform container details.
2024-08-12 02:22:01,326 [rdaf.component.platform] INFO - Gathering rdac pod details.
+----------+----------------------+---------+---------+--------------+-------------+------------+
| Pod ID | Pod Type | Version | Age | Hostname | Maintenance | Pod Status |
+----------+----------------------+---------+---------+--------------+-------------+------------+
| 3a5ff878 | api-server | 3.4.2.1 | 2:34:09 | 5119921f9c1c | None | True |
| 689c2574 | registry | 3.4.2 | 3:23:10 | d21676c0465b | None | True |
| 0d03f649 | scheduler | 3.4.2.1 | 2:34:46 | dd699a1d15af | None | True |
| 0496910a | collector | 3.4.2 | 3:22:40 | 1c367e3bf00a | None | True |
| c4a88eb7 | asset-dependency | 3.4.2 | 3:22:25 | cdb3f4c76deb | None | True |
| 9562960a | authenticator | 3.4.2 | 3:22:09 | 8bda6c86a264 | None | True |
| ae8b58e5 | asm | 3.4.2 | 3:21:54 | 8f0f7f773907 | None | True |
| 1cea350e | fsm | 3.4.2 | 3:21:37 | 1ea1f5794abb | None | True |
| 32fa2f93 | chat-helper | 3.4.2 | 3:21:23 | 811cbcfba7a2 | None | True |
| 0e6f375c | cfxdimensions-app- | 3.4.2 | 3:21:07 | 307c140f99c2 | None | True |
| | access-manager | | | | | |
| 4130b2d4 | cfxdimensions-app- | 3.4.2.2 | 2:24:23 | 2d73c36426fe | None | True |
| | resource-manager | | | | | |
| 29caf947 | user-preferences | 3.4.2 | 3:20:36 | 3e2b5b7e6cb4 | None | True |
+----------+----------------------+---------+---------+--------------+-------------+------------+
Continue moving above pods to maintenance mode? [yes/no]: yes
2024-08-12 02:23:04,389 [rdaf.component.platform] INFO - Initiating Maintenance Mode...
2024-08-12 02:23:10,048 [rdaf.component.platform] INFO - Following container are in maintenance mode
+----------+----------------------+---------+---------+--------------+-------------+------------+
| Pod ID | Pod Type | Version | Age | Hostname | Maintenance | Pod Status |
+----------+----------------------+---------+---------+--------------+-------------+------------+
| 3a5ff878 | api-server | 3.4.2.1 | 2:34:49 | 5119921f9c1c | maintenance | False |
| ae8b58e5 | asm | 3.4.2 | 3:22:34 | 8f0f7f773907 | maintenance | False |
| c4a88eb7 | asset-dependency | 3.4.2 | 3:23:05 | cdb3f4c76deb | maintenance | False |
| 9562960a | authenticator | 3.4.2 | 3:22:49 | 8bda6c86a264 | maintenance | False |
| 0e6f375c | cfxdimensions-app- | 3.4.2 | 3:21:47 | 307c140f99c2 | maintenance | False |
| | access-manager | | | | | |
| 4130b2d4 | cfxdimensions-app- | 3.4.2.2 | 2:25:03 | 2d73c36426fe | maintenance | False |
| | resource-manager | | | | | |
| 32fa2f93 | chat-helper | 3.4.2 | 3:22:03 | 811cbcfba7a2 | maintenance | False |
| 0496910a | collector | 3.4.2 | 3:23:20 | 1c367e3bf00a | maintenance | False |
| 1cea350e | fsm | 3.4.2 | 3:22:17 | 1ea1f5794abb | maintenance | False |
| 689c2574 | registry | 3.4.2 | 3:23:50 | d21676c0465b | maintenance | False |
| 0d03f649 | scheduler | 3.4.2.1 | 2:35:26 | dd699a1d15af | maintenance | False |
| 29caf947 | user-preferences | 3.4.2 | 3:21:16 | 3e2b5b7e6cb4 | maintenance | False |
+----------+----------------------+---------+---------+--------------+-------------+------------+
2024-08-12 02:23:10,052 [rdaf.component.platform] INFO - Waiting for timeout of 5 seconds...
2024-08-12 02:23:15,060 [rdaf.component.platform] INFO - Upgrading service: rda_api_server on host 192.168.133.92
Run the below command to initiate upgrading RDAF Platform services without zero downtime
Please wait till all of the new platform services are in Up state and run the below command to verify their status and make sure all of them are running with 3.5 version.
+--------------------------+----------------+------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+--------------------------+----------------+------------+--------------+-------+
| rda_api_server | 192.168.133.92 | Up 2 hours | 1b0542719618 | 3.5 |
| rda_api_server | 192.168.133.93 | Up 2 hours | d4404cffdc7a | 3.5 |
| rda_registry | 192.168.133.92 | Up 2 hours | 7db3e3b7e294 | 3.5 |
| rda_registry | 192.168.133.93 | Up 2 hours | 3adfc2db2735 | 3.5 |
| rda_scheduler | 192.168.133.92 | Up 2 hours | 7fbdaf30ad05 | 3.5 |
| rda_scheduler | 192.168.133.93 | Up 2 hours | cf3280d11a4d | 3.5 |
| rda_collector | 192.168.133.92 | Up 2 hours | d0e5d30e3aba | 3.5 |
| rda_collector | 192.168.133.93 | Up 2 hours | 2d6b8d14add0 | 3.5 |
| rda_asset_dependency | 192.168.133.92 | Up 2 hours | 6ac69ca1085c | 3.5 |
| rda_asset_dependency | 192.168.133.93 | Up 2 hours | 58a5f4f460d3 | 3.5 |
| rda_identity | 192.168.133.92 | Up 2 hours | 9011c2aef498 | 3.5 |
| rda_identity | 192.168.133.93 | Up 2 hours | 148621ed8c82 | 3.5 |
| rda_asm | 192.168.133.92 | Up 2 hours | 8d3d52a7a475 | 3.5 |
| rda_asm | 192.168.133.93 | Up 2 hours | ab172a9b8229 | 3.5 |
| rda_fsm | 192.168.133.92 | Up 2 hours | 9c42d42c6b10 | 3.5 |
| rda_fsm | 192.168.133.93 | Up 2 hours | 60803ace9f18 | 3.5 |
| rda_chat_helper | 192.168.133.92 | Up 2 hours | 3bb8a356844c | 3.5 |
| rda_chat_helper | 192.168.133.93 | Up 2 hours | b56eb65ef88d | 3.5 |
+--------------------------+----------------+------------+--------------+-------+
Run the below command to check the rda-scheduler service is elected as a leader under Site column.
Run the below command to check if all services has ok status and does not throw any failure messages.
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------+
| Cat | Pod-Type | Host | ID | Site | Health Parameter | Status | Message |
|-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------|
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-status | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | minio-connectivity | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-initialization-status | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | kafka-connectivity | ok | Cluster=NTc1NWU1MTQxYmY3MTFlZg, Broker=1, Brokers=[1, 2, 3] |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-status | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | minio-connectivity | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-initialization-status | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | kafka-connectivity | ok | Cluster=NTc1NWU1MTQxYmY3MTFlZg, Broker=3, Brokers=[1, 2, 3] |
| rda_app | alert-processor | c6cc7b04ab33 | b4ebfb06 | | service-status | ok | |
| rda_app | alert-processor | c6cc7b04ab33 | b4ebfb06 | | minio-connectivity | ok | |
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------+
Redis service cleanup:
Run the Python script below to clean up the redis infrastructure service. This script will:
- Shut down the redis service.
- Clear configuration data in
/opt/rdaf/rdaf.cfgand/opt/rdaf/deployment-scripts/<infra-service-host-ip>/infra.yaml
- Run the below mentioned command to check if redis service containers are decommissioned and no longer visible.
1.3.3 Upgrade rdac CLI
1.3.4 Upgrade RDA Worker Services
Step-1: Please run the below command to initiate upgrading the RDA Worker service PODs.
Step-2: Run the below command to check the status of the existing and newer PODs and make sure atleast one instance of each RDA Worker service POD is in Terminating state.
NAME READY STATUS RESTARTS AGE
rda-worker-77f459d5b9-9kdmg 1/1 Running 0 73m
rda-worker-77f459d5b9-htsmr 1/1 Running 0 74m
Step-3: Run the below command to put all Terminating RDAF worker service PODs into maintenance mode. It will list all of the POD Ids of RDA worker services along with rdac maintenance command that is required to be put in maintenance mode.
Step-4: Copy & Paste the rdac maintenance command as below.
Step-5: Run the below command to verify the maintenance mode status of the RDAF worker services.
Step-6: Run the below command to delete the Terminating RDAF worker service PODs
for i in `kubectl get pods -n rda-fabric -l app_component=rda-worker | grep 'Terminating' | awk '{print $1}'`; do kubectl delete pod $i -n rda-fabric --force; done
Note
Wait for 120 seconds between each RDAF worker service upgrade by repeating above steps from Step-2 to Step-6 for rest of the RDAF worker service PODs.
Step-7: Please wait for 120 seconds to let the newer version of RDA Worker service PODs join the RDA Fabric appropriately. Run the below commands to verify the status of the newer RDA Worker service PODs.
+------------+----------------+-----------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+------------+----------------+-----------------+--------------+-------+
| rda-worker | 192.168.108.17 | Up 19 Hours ago | d724c123dff8 | 3.5 |
| rda-worker | 192.168.108.18 | Up 19 Hours ago | cf5dd7e67d15 | 3.5 |
+------------+----------------+-----------------+--------------+-------+
Step-8: Run the below command to check if all RDA Worker services has ok status and does not throw any failure messages.
- Upgrade RDA Worker Services
Please run the below command to initiate upgrading the RDA Worker Service with zero downtime
Note
timeout <10> mentioned in the above command represents as seconds
Note
The rolling-upgrade option upgrades the Worker services running in high-availability mode on one VM at a time in sequence. It completes the upgrade of Worker services running on VM-1 before upgrading them on VM-2, followed by VM-3, and so on.
After completing the Worker services upgrade on all VMs, it will ask for user confirmation to delete the older version Worker service PODs.
2024-08-12 02:56:11,573 [rdaf.component.worker] INFO - Collecting worker details for rolling upgrade
2024-08-12 02:56:14,301 [rdaf.component.worker] INFO - Rolling upgrade worker on 192.168.133.96
+----------+----------+---------+---------+--------------+-------------+------------+
| Pod ID | Pod Type | Version | Age | Hostname | Maintenance | Pod Status |
+----------+----------+---------+---------+--------------+-------------+------------+
| c8a37db9 | worker | 3.4.2.1 | 3:32:31 | fffe44b43708 | None | True |
+----------+----------+---------+---------+--------------+-------------+------------+
Continue moving above pod to maintenance mode? [yes/no]: yes
2024-08-12 02:57:17,346 [rdaf.component.worker] INFO - Initiating maintenance mode for pod c8a37db9
2024-08-12 02:57:22,401 [rdaf.component.worker] INFO - Waiting for worker to be moved to maintenance.
2024-08-12 02:57:35,001 [rdaf.component.worker] INFO - Following worker container is in maintenance mode
+----------+----------+---------+---------+--------------+-------------+------------+
| Pod ID | Pod Type | Version | Age | Hostname | Maintenance | Pod Status |
+----------+----------+---------+---------+--------------+-------------+------------+
| c8a37db9 | worker | 3.4.2.1 | 3:33:52 | fffe44b43708 | maintenance | False |
+----------+----------+---------+---------+--------------+-------------+------------+
2024-08-12 02:57:35,002 [rdaf.component.worker] INFO - Waiting for timeout of 3 seconds.
Please run the below command to initiate upgrading the RDA Worker Service without zero downtime
Please wait for 120 seconds to let the newer version of RDA Worker service containers join the RDA Fabric appropriately. Run the below commands to verify the status of the newer RDA Worker service containers.
| Infra | worker | True | 6eff605e72c4 | a318f394 | rda-site-01 | 13:45:13 | 4 | 31.21 | 0 | 0 |
| Infra | worker | True | ae7244d0d10a | 554c2cd8 | rda-site-01 | 13:40:40 | 4 | 31.21 | 0 | 0 |
+------------+----------------+---------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+------------+----------------+---------------+--------------+-------+
| rda_worker | 192.168.133.92 | Up 57 minutes | 039155860c55 | 3.5 |
| rda_worker | 192.168.133.96 | Up 57 minutes | 57955572f4c9 | 3.5 |
+------------+----------------+---------------+--------------+-------+
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+
| Cat | Pod-Type | Host | ID | Site | Health Parameter | Status | Message |
|-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-----------------------------------------------------------------------------------------------------------------------------|
| rda_infra | api-server | 1b0542719618 | 1845ae67 | | service-status | ok | |
| rda_infra | api-server | 1b0542719618 | 1845ae67 | | minio-connectivity | ok | |
| rda_infra | api-server | d4404cffdc7a | a4cfdc6d | | service-status | ok | |
| rda_infra | api-server | d4404cffdc7a | a4cfdc6d | | minio-connectivity | ok | |
| rda_infra | asm | 8d3d52a7a475 | 418c9dc1 | | service-status | ok | |
| rda_infra | asm | 8d3d52a7a475 | 418c9dc1 | | minio-connectivity | ok | |
| rda_infra | asm | ab172a9b8229 | 2ac1d67a | | service-status | ok | |
| rda_infra | asm | ab172a9b8229 | 2ac1d67a | | minio-connectivity | ok | |
| rda_app | asset-dependency | 6ac69ca1085c | c2e9dcb9 | | service-status | ok | |
| rda_app | asset-dependency | 6ac69ca1085c | c2e9dcb9 | | minio-connectivity | ok | |
| rda_app | asset-dependency | 58a5f4f460d3 | 0b91caac | | service-status | ok | |
| rda_app | asset-dependency | 58a5f4f460d3 | 0b91caac | | minio-connectivity | ok | |
| rda_app | authenticator | 9011c2aef498 | 9f7efdc3 | | service-status | ok | |
| rda_app | authenticator | 9011c2aef498 | 9f7efdc3 | | minio-connectivity | ok | |
| rda_app | authenticator | 9011c2aef498 | 9f7efdc3 | | DB-connectivity | ok | |
| rda_app | authenticator | 148621ed8c82 | dbf16b82 | | service-status | ok | |
| rda_app | authenticator | 148621ed8c82 | dbf16b82 | | minio-connectivity | ok | |
| rda_app | authenticator | 148621ed8c82 | dbf16b82 | | DB-connectivity | ok | |
| rda_app | cfx-app-controller | 75ec0f30cfa3 | 1198fdee | | service-status | ok | |
| rda_app | cfx-app-controller | 75ec0f30cfa3 | 1198fdee | | minio-connectivity | ok | |
| rda_app | cfx-app-controller | 75ec0f30cfa3 | 1198fdee | | service-initialization-status | ok | |
| rda_app | cfx-app-controller | 75ec0f30cfa3 | 1198fdee | | DB-connectivity | ok |
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+
Note
If the worker is deployed in a proxy environment, please add the required environment proxy variables in /opt/rdaf/deployment-scripts/values.yaml, under the section 'rda_worker' -> 'env:', instead of making changes to worker.yaml (This is recommended only if there are any new changes needed for the worker)
1.3.5 Upgrade OIA Application Services
Step-1: Run the below commands to initiate upgrading RDAF OIA Application services
Step-2: Run the below command to check the status of the newly upgraded PODs.
Step-3: Run the below command to put all Terminating OIA application service PODs into maintenance mode. It will list all of the POD Ids of OIA application services along with rdac maintenance command that are required to be put in maintenance mode.
Step-4: Copy & Paste the rdac maintenance command as below.
Step-5: Run the below command to verify the maintenance mode status of the OIA application services.
Step-6: Run the below command to delete the Terminating OIA application service PODs
for i in `kubectl get pods -n rda-fabric -l app_name=oia | grep 'Terminating' | awk '{print $1}'`; do kubectl delete pod $i -n rda-fabric --force; done
Note
Wait for 120 seconds and Repeat above steps from Step-2 to Step-6 for rest of the OIA application service PODs.
Please wait till all of the new OIA application service PODs are in Running state and run the below command to verify their status and make sure they are running with 7.5 version.
+-------------------------------+----------------+-----------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+-------------------------------+----------------+-----------------+--------------+-------+
| rda-alert-ingester | 192.168.108.17 | Up 19 Hours ago | 0e46a7dd6f90 | 7.5 |
| rda-alert-ingester | 192.168.108.18 | Up 19 Hours ago | 3fdada0f4982 | 7.5 |
| rda-alert-processor | 192.168.108.20 | Up 19 Hours ago | 8edcf5ac9ffb | 7.5 |
| rda-alert-processor | 192.168.108.19 | Up 19 Hours ago | bc2c1adb91cb | 7.5 |
| rda-alert-processor-companion | 192.168.108.17 | Up 19 Hours ago | 52f7c68bc89d | 7.5 |
| rda-alert-processor-companion | 192.168.108.18 | Up 19 Hours ago | e481a28bdc48 | 7.5 |
| rda-app-controller | 192.168.108.17 | Up 19 Hours ago | 4418f95602a0 | 7.5 |
| rda-app-controller | 192.168.108.18 | Up 19 Hours ago | 8a026184c739 | 7.5 |
| rda-collaboration | 192.168.108.18 | Up 19 Hours ago | b284089c722f | 7.5 |
| rda-collaboration | 192.168.108.17 | Up 19 Hours ago | e06666cc9d86 | 7.5 |
| rda-configuration-service | 192.168.108.17 | Up 19 Hours ago | db6276308ac8 | 7.5 |
| rda-configuration-service | 192.168.108.18 | Up 19 Hours ago | c8a781f00c04 | 7.5 |
+-------------------------------+----------------+-----------------+--------------+-------+
Step-7: Run the below command to verify all OIA application services are up and running.
+-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------+
| Cat | Pod-Type | Pod-Ready | Host | ID | Site | Age | CPUs | Memory(GB) | Active Jobs | Total Jobs |
|-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------|
| App | alert-ingester | True | rda-alert-inge | 6a6e464d | | 19:19:06 | 8 | 31.33 | | |
| App | alert-ingester | True | rda-alert-inge | 7f6b42a0 | | 19:19:23 | 8 | 31.33 | | |
| App | alert-processor | True | rda-alert-proc | a880e491 | | 19:19:51 | 8 | 31.33 | | |
| App | alert-processor | True | rda-alert-proc | b684609e | | 19:19:48 | 8 | 31.33 | | |
| App | alert-processor-companion | True | rda-alert-proc | 874f3b33 | | 19:18:54 | 8 | 31.33 | | |
| App | alert-processor-companion | True | rda-alert-proc | 70cadaa7 | | 19:18:35 | 8 | 31.33 | | |
| App | asset-dependency | True | rda-asset-depe | bde06c15 | | 19:44:20 | 8 | 31.33 | | |
| App | asset-dependency | True | rda-asset-depe | 47b9eb02 | | 19:44:08 | 8 | 31.33 | | |
| App | authenticator | True | rda-identity-d | faa33e1b | | 19:44:22 | 8 | 31.33 | | |
| App | authenticator | True | rda-identity-d | 36083c36 | | 19:44:16 | 8 | 31.33 | | |
| App | cfx-app-controller | True | rda-app-contro | 5fd3c3f4 | | 19:19:39 | 8 | 31.33 | | |
| App | cfx-app-controller | True | rda-app-contro | d66e5ce8 | | 19:19:26 | 8 | 31.33 | | |
| App | cfxdimensions-app-access-manager | True | rda-access-man | ecbb535c | | 19:44:16 | 8 | 31.33 | | |
| App | cfxdimensions-app-access-manager | True | rda-access-man | 9a05db5a | | 19:44:06 | 8 | 31.33 | | |
| App | cfxdimensions-app-collaboration | True | rda-collaborat | 61b3c53b | | 19:18:48 | 8 | 31.33 | | |
| App | cfxdimensions-app-collaboration | True | rda-collaborat | 09b9474e | | 19:18:27 | 8 | 31.33 | | |
+-------+----------------------------------------+-------------+----------------+----------+-------------+-------------------+--------+-----------------------------+--------------+
Run the below command to check if all services has ok status and does not throw any failure messages.
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+
| Cat | Pod-Type | Host | ID | Site | Health Parameter | Status | Message |
|-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-----------------------------------------------------------------------------------------------------------------------------|
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | service-status | ok | |
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | minio-connectivity | ok | |
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | service-initialization-status | ok | |
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | kafka-connectivity | ok | Cluster=dKnnkaYSPELK8DBUk0rPig, Broker=0, Brokers=[0, 1, 2] |
| rda_app | alert-ingester | rda-alert-in | 6a6e464d | | kafka-consumer | ok | Health: [{'387c0cb507b84878b9d0b15222cb4226.inbound-events': 0, '387c0cb507b84878b9d0b15222cb4226.mapped-events': 0}, {}] |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | service-status | ok | |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | minio-connectivity | ok | |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | service-initialization-status | ok | |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | kafka-consumer | ok | Health: [{'387c0cb507b84878b9d0b15222cb4226.inbound-events': 0, '387c0cb507b84878b9d0b15222cb4226.mapped-events': 0}, {}] |
| rda_app | alert-ingester | rda-alert-in | 7f6b42a0 | | kafka-connectivity | ok | Cluster=dKnnkaYSPELK8DBUk0rPig, Broker=1, Brokers=[0, 1, 2] |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | service-status | ok | |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | minio-connectivity | ok | |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | service-dependency:cfx-app-controller | ok | 2 pod(s) found for cfx-app-controller |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | service-initialization-status | ok | |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | kafka-connectivity | ok | Cluster=dKnnkaYSPELK8DBUk0rPig, Broker=1, Brokers=[0, 1, 2] |
| rda_app | alert-processor | rda-alert-pr | a880e491 | | DB-connectivity | ok | |
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------+
Run the below commands to initiate upgrading the RDA Fabric OIA Application services with zero downtime
Note
timeout <10> mentioned in the above command represents as Seconds
Note
The rolling-upgrade option upgrades the OIA application services running in high-availability mode on one VM at a time in sequence. It completes the upgrade of OIA application services running on VM-1 before upgrading them on VM-2, followed by VM-3, and so on.
After completing the OIA application services upgrade on all VMs, it will ask for user confirmation to delete the older version OIA application service PODs.
2024-08-12 03:18:08,705 [rdaf.component.oia] INFO - Gathering OIA app container details.
2024-08-12 03:18:10,719 [rdaf.component.oia] INFO - Gathering rdac pod details.
+----------+----------------------+---------+---------+--------------+-------------+------------+
| Pod ID | Pod Type | Version | Age | Hostname | Maintenance | Pod Status |
+----------+----------------------+---------+---------+--------------+-------------+------------+
| 2992fe69 | cfx-app-controller | 7.4.2 | 3:44:53 | 0500f773a8ff | None | True |
| 336138c8 | reports-registry | 7.4.2 | 3:44:12 | 92a5e0daa942 | None | True |
| ccc5f3ce | cfxdimensions-app- | 7.4.2 | 3:43:34 | 99192de47ea4 | None | True |
| | notification-service | | | | | |
| 03614007 | cfxdimensions-app- | 7.4.2 | 3:42:54 | fbdf4e5c16c3 | None | True |
| | file-browser | | | | | |
| a4949804 | configuration- | 7.4.2 | 3:42:15 | 4ea08c8cbf2e | None | True |
| | service | | | | | |
| 8f37c520 | alert-ingester | 7.4.2 | 3:41:35 | e9e3a3e69cac | None | True |
| 249b7104 | webhook-server | 7.4.2.1 | 3:12:04 | 1df43cebc888 | None | True |
| 76c64336 | smtp-server | 7.4.2.1 | 3:08:57 | 03725b0cb91f | None | True |
| ad85cb4c | event-consumer | 7.4.2.1 | 3:09:58 | 8a7d349da513 | None | True |
| 1a788ef3 | alert-processor | 7.4.2.1 | 3:11:01 | a7c5294cba3d | None | True |
| 970b90b1 | cfxdimensions-app- | 7.4.2 | 3:38:14 | 01d4245bb90e | None | True |
| | irm_service | | | | | |
| 153aa6ac | ml-config | 7.4.2 | 3:37:33 | 10d5d6766354 | None | True |
| 5aa927a4 | cfxdimensions-app- | 7.4.2 | 3:36:53 | dcfda7175cb5 | None | True |
| | collaboration | | | | | |
| 6833aa86 | ingestion-tracker | 7.4.2 | 3:36:13 | ef0e78252e48 | None | True |
| afe77cb9 | alert-processor- | 7.4.2 | 3:35:33 | 6f03c7fdba51 | None | True |
| | companion | | | | | |
+----------+----------------------+---------+---------+--------------+-------------+------------+
Continue moving above pods to maintenance mode? [yes/no]: yes
2024-08-12 03:18:27,159 [rdaf.component.oia] INFO - Initiating Maintenance Mode...
2024-08-12 03:18:32,978 [rdaf.component.oia] INFO - Waiting for services to be moved to maintenance.
2024-08-12 03:18:55,771 [rdaf.component.oia] INFO - Following container are in maintenance mode
+----------+----------------------+---------+---------+--------------+-------------+------------+
Run the below command to initiate upgrading the RDA Fabric OIA Application services without zero downtime
Please wait till all of the new OIA application service containers are in Up state and run the below command to verify their status and make sure they are running with 7.5 version.
+--------------------+------------ --+------------+--------------+-----+
| Name | Host | Status | Container Id | Tag |
+--------------------+------------ --+------------+--------------+-----+
| cfx-rda-app- | 192.168.133.96 | Up 4 hours | f139e2b3cca3 | 7.5 |
| controller | | | | |
| cfx-rda-app- | 192.168.133.92 | Up 3 hours | 6d68b737715a | 7.5 |
| controller | | | | |
| cfx-rda-reports- | 192.168.133.96 | Up 4 hours | 0a6bac884dff | 7.5 |
| registry | | | | |
| cfx-rda-reports- | 192.168.133.92 | Up 3 hours | 3477e7f751ec | 7.5 |
| registry | | | | |
| cfx-rda- | 192.168.133.96 | Up 4 hours | 96dd2337f779 | 7.5 |
| notification- | | | | |
| service | | | | |
| cfx-rda- | 192.168.133.92 | Up 3 hours | 3a1743239a99 | 7.5 |
| notification- | | | | |
| service | | | | |
| cfx-rda-file- | 192.168.133.96 | Up 3 hours | bd41100a456c | 7.5 |
| browser | | | | |
| cfx-rda-file- | 192.168.133.92 | Up 3 hours | 2cc517b8a640 | 7.5 |
| browser | | | | |
| cfx-rda- | 192.168.133.96 | Up 3 hours | 9f1e53602999 | 7.5 |
| configuration- | | | | |
| service | | | | |
| cfx-rda- | 192.168.133.92 | Up 3 hours | 8e50e464bcd5 | 7.5 |
| configuration- | | | | |
| service | | | | |
| cfx-rda-alert- | 192.168.133.96 | Up 3 hours | 7f75047e9e44 | 7.5 |
| ingester | | | | |
| cfx-rda-alert- | 192.168.133.92 | Up 3 hours | f9ec55862be0 | 7.5 |
| ingester | | | | |
+--------------------+----------------+------------+--------------+-----+
Run the below command to verify all OIA application services are up and running.
+-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------+
| Cat | Pod-Type | Pod-Ready | Host | ID | Site | Age | CPUs | Memory(GB) | Active Jobs | Total Jobs |
|-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------|
| App | alert-ingester | True | rda-alert-inge | 6a6e464d | | 19:22:36 | 8 | 31.33 | | |
| App | alert-ingester | True | rda-alert-inge | 7f6b42a0 | | 19:22:53 | 8 | 31.33 | | |
| App | alert-processor | True | rda-alert-proc | a880e491 | | 19:23:21 | 8 | 31.33 | | |
| App | alert-processor | True | rda-alert-proc | b684609e | | 19:23:18 | 8 | 31.33 | | |
| App | alert-processor-companion | True | rda-alert-proc | 874f3b33 | | 19:22:24 | 8 | 31.33 | | |
| App | alert-processor-companion | True | rda-alert-proc | 70cadaa7 | | 19:22:05 | 8 | 31.33 | | |
| App | asset-dependency | True | rda-asset-depe | bde06c15 | | 19:47:50 | 8 | 31.33 | | |
| App | asset-dependency | True | rda-asset-depe | 47b9eb02 | | 19:47:38 | 8 | 31.33 | | |
| App | authenticator | True | rda-identity-d | faa33e1b | | 19:47:52 | 8 | 31.33 | | |
| App | authenticator | True | rda-identity-d | 36083c36 | | 19:47:46 | 8 | 31.33 | | |
| App | cfx-app-controller | True | rda-app-contro | 5fd3c3f4 | | 19:23:09 | 8 | 31.33 | | |
| App | cfx-app-controller | True | rda-app-contro | d66e5ce8 | | 19:22:56 | 8 | 31.33 | | |
| App | cfxdimensions-app-access-manager | True | rda-access-man | ecbb535c | | 19:47:46 | 8 | 31.33 | | |
| App | cfxdimensions-app-access-manager | True | rda-access-man | 9a05db5a | | 19:47:36 | 8 | 31.33 | | |
| App | cfxdimensions-app-collaboration | True | rda-collaborat | 61b3c53b | | 19:22:18 | 8 | 31.33 | | |
| App | cfxdimensions-app-collaboration | True | rda-collaborat | 09b9474e | | 19:21:57 | 8 | 31.33 | | |
| App | cfxdimensions-app-file-browser | True | rda-file-brows | 00495640 | | 19:22:45 | 8 | 31.33 | | |
| App | cfxdimensions-app-file-browser | True | rda-file-brows | 640f0653 | | 19:22:29 | 8 | 31.33 | | |
| App | cfxdimensions-app-irm_service | True | rda-irm-servic | 27e345c5 | | 19:21:43 | 8 | 31.33 | | |
| App | cfxdimensions-app-irm_service | True | rda-irm-servic | 23c7e082 | | 19:21:56 | 8 | 31.33 | | |
| App | cfxdimensions-app-notification-service | True | rda-notificati | bbb5b08b | | 19:23:20 | 8 | 31.33 | | |
| App | cfxdimensions-app-notification-service | True | rda-notificati | 9841bcb5 | | 19:23:02 | 8 | 31.33 | | |
+-------+----------------------------------------+-------------+----------------+----------+-------------+----------+--------+--------------+---------------+--------------+
Run the below command to check if all services has ok status and does not throw any failure messages.
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------+
| Cat | Pod-Type | Host | ID | Site | Health Parameter | Status | Message |
|-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------|
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-status | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | minio-connectivity | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | service-initialization-status | ok | |
| rda_app | alert-ingester | 7f75047e9e44 | daa8c414 | | kafka-connectivity | ok | Cluster=NTc1NWU1MTQxYmY3MTFlZg, Broker=1, Brokers=[1, 2, 3] |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-status | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | minio-connectivity | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-dependency:configuration-service | ok | 2 pod(s) found for configuration-service |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | service-initialization-status | ok | |
| rda_app | alert-ingester | f9ec55862be0 | f9b9231c | | kafka-connectivity | ok | Cluster=NTc1NWU1MTQxYmY3MTFlZg, Broker=2, Brokers=[1, 2, 3] |
| rda_app | alert-processor | c6cc7b04ab33 | b4ebfb06 | | service-status | ok | |
| rda_app | alert-processor | c6cc7b04ab33 | b4ebfb06 | | minio-connectivity | ok | |
+-----------+----------------------------------------+--------------+----------+-------------+-----------------------------------------------------+----------+-------------------------------------------------------------+
1.3.6 Upgrade Event Gateway Services
Important
This Upgrade is for Non-K8s only
1. Prerequisites
- Event Gateway with 3.4.2 tag should be already installed
2. Upgrade Event Gateway Using RDAF CLI
-
To upgrade the event gateway, log in to the rdaf cli VM and execute the following command.
Note
If user deployed the event gateway using the RDAF CLI, follow the above mentioned step.
3. Upgrade Event Gateway Using Docker Compose File
-
Login to the Event Gateway installed VM
-
Navigate to the location where Event Gateway was previously installed, using the following command
-
Edit the docker-compose file for the Event Gateway using a local editor (e.g. vi) update the tag and save it
version: '3.1' services: rda_event_gateway: image: cfxregistry.cloudfabrix.io/ubuntu-rda-event-gateway:3.5 restart: always network_mode: host mem_limit: 6G memswap_limit: 6G volumes: - /opt/rdaf/network_config:/network_config - /opt/rdaf/event_gateway/config:/event_gw_config - /opt/rdaf/event_gateway/certs:/certs - /opt/rdaf/event_gateway/logs:/logs - /opt/rdaf/event_gateway/log_archive:/tmp/log_archive logging: driver: "json-file" options: max-size: "25m" max-file: "5" environment: RDA_NETWORK_CONFIG: /network_config/rda_network_config.json EVENT_GW_MAIN_CONFIG: /event_gw_config/main/main.yml EVENT_GW_SNMP_TRAP_CONFIG: /event_gw_config/snmptrap/trap_template.json EVENT_GW_SNMP_TRAP_ALERT_CONFIG: /event_gw_config/snmptrap/trap_to_alert_go.yaml AGENT_GROUP: event_gateway_site01 EVENT_GATEWAY_CONFIG_DIR: /event_gw_config LOGGER_CONFIG_FILE: /event_gw_config/main/logging.yml -
Please run the following commands
-
Use the command as shown below to ensure that the RDA docker instances are up and running.
-
Use the below mentioned command to check docker logs for any errors
1.3.7 Upgrade RDA Edge Collector Service
Important
This Upgrade is for Non-K8s only
Step 1. Enter the login credentials for the VM where the EC agent is installed
Step 2. Navigate to the location where the EC agent was originally installed. view the Example provided below.
Step 3. Use a local editor to make changes to the EC agent's docker-compose file (e.g. vi).- Edit and update EC agent tag – Tag x → Tag 3.5, view the Example provided below
Step 4. Save & Exit
Step 5. Please execute these commands to bring up the RDA Edge Collector from path
cd /opt/rdaf/edgecollectordocker-compose -f rda-edgecollector-docker-compose.yml down docker-compose -f rda-edgecollector-docker-compose.yml pull docker-compose -f rda-edgecollector-docker-compose.yml up -dStep 6. To make sure the RDA Docker Edge Collector Instance are up and running, use the following command as shown below.
1.3.8 Setup & Install Self Monitoring
In RDAF platform version 3.5, the RDAF CLI now supports installing and configuring the self_monitoring service. This service helps monitor the functional health of RDAF platform services and sends notifications via Slack, Webex Teams, or other collaboration tools.
For detailed information, please refer CFX Self Monitor Service
- Please run the below command to setup Self Monitoring
The user must enter the necessary parameters as indicated in the screenshot below Example.
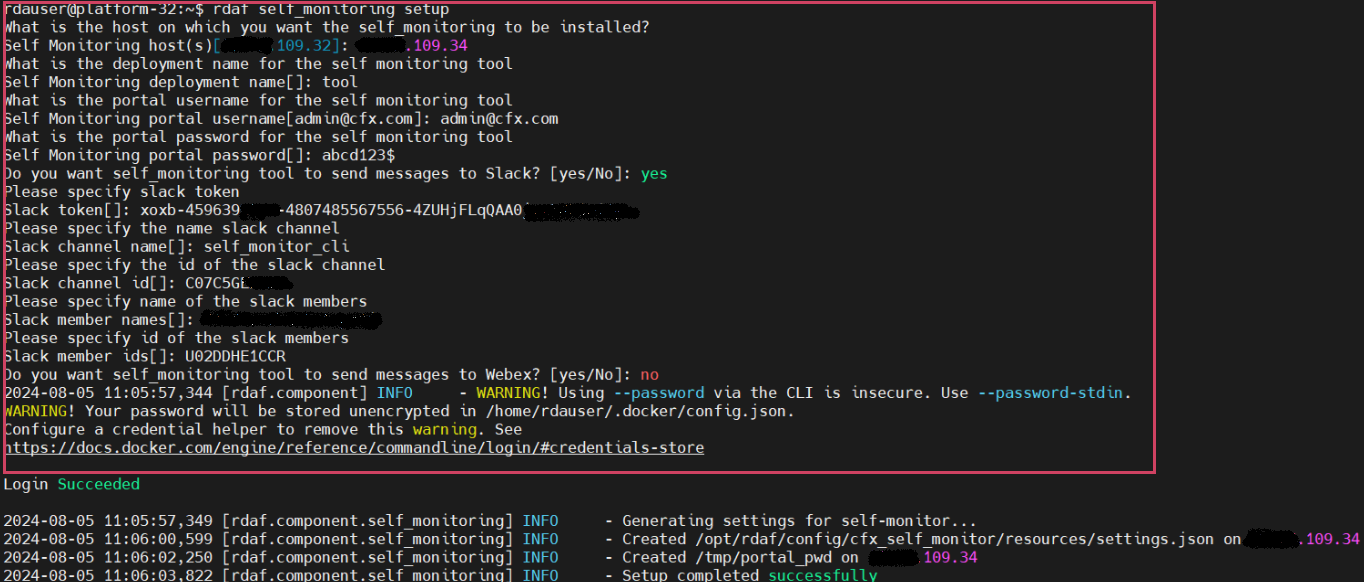
- Run the below command to install Self Monitoring
- Run the below command to verify the status
+------------------+----------------+-------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+------------------+----------------+-------------+--------------+-------+
| cfx_self_monitor | 192.168.108.20 | Up 23 hours | 4aca96ccfba4 | 3.5 |
+------------------+----------------+-------------+--------------+-------+
- Please run the below command to setup Self Monitoring
The user must enter the necessary parameters as indicated in the screenshot below Example.
- Run the below command to install Self Monitoring
- Run the below command to verify the status
+------------------+----------------+-------------+--------------+-------+
| Name | Host | Status | Container Id | Tag |
+------------------+----------------+-------------+--------------+-------+
| cfx_self_monitor | 192.168.109.24 | Up 23 hours | 5c468d35f3d4 | 3.5 |
+------------------+----------------+-------------+--------------+-------+
1.4.Post Upgrade Steps
1. Deploy latest Alerts and Incidents Dashboard configuration
Go to Main Menu --> Configuration --> RDA Administration --> Bundles --> Select oia_l1_l2_bundle and Click on Deploy action to deploy the latest Dashboards configuration for Alerts and Incidents.
For the document on Alert Dashboard Changes from 7.4.2 to 7.5, Please Click Here
Note
If any custom dashboards were made for Alert Dashboards in the previous release(7.4.2), only then the above mentioned Alert Dashboard Changes is necessary. If not, step 1 will handle the Alert Dashboard Changes.
For the document on GraphDB if its already installed, we have a new feature in UI to access GraphDB data, for more details on this Please Click Here
Note
Make sure that the purging durations for both the database and Pstream are aligned. For the document on Purge Configuration please Click Here
Streams:
-
oia-incidents-stream
-
oia-alerts-stream
1. Deploy latest Alerts and Incidents Dashboard configuration
Go to Main Menu --> Configuration --> RDA Administration --> Bundles --> Select oia_l1_l2_bundle and Click on Deploy action to deploy the latest Dashboards configuration for Alerts and Incidents.
For the document on Alert Dashboard Changes from 7.4.2 to 7.5, Please Click Here
Note
If any custom dashboards were made for Alert Dashboards in the previous release(7.4.2), only then the above mentioned Alert Dashboard Changes is necessary. If not, step 1 will handle the Alert Dashboard Changes.
For the document on GraphDB if its already installed, we have a new feature in UI to access GraphDB data, for more details on this Please Click Here
Note
Make sure that the purging durations for both the database and Pstream are aligned. For the document on Purge Configuration please Click Here
Streams:
-
oia-incidents-stream
-
oia-alerts-stream
1.5 Upgrade from 3.7 to 3.7.1 and 7.7 to 7.7.1
- Please follow the steps mentioned in the document for upgrading the selective services from 3.7 to 3.7.1 and 7.7 to 7.7.1, For the document please Click Here